- AWS In Bites
- Posts
- DynamoDB Streams
DynamoDB Streams
Part 1: Fundamental Concepts and Core Patterns
Chris Gonzalez
September 02, 2024

Introduction
DynamoDB Streams is a powerful feature of the DynamoDB service that captures data modifications within your tables in near real-time, enabling you to build responsive, event-driven applications. At the fundamental level, a stream is a time-ordered sequence of item level changes that in turn allows your applications to respond to data updates as they happen. There are many real-world use cases for DynamoDB streams. A few examples include shopping cart updates, financial transaction processing, or social media post update or creation flows. As builders, we must understand how this concept works and some core architecture patterns and considerations. This discussion will include both Kinesis Data Streams for DynamoDB and DynamoDB streams. If a concept differs between the two, you’ll see a note.
Understanding DynamoDB Stream Records
When item level changes occur in a DynamoDB table, these changes are captured in a time-ordered sequence called a stream. Additionally, every modification to a table item will be captured.
Anatomy of a Stream Record
Each record in the stream tells us a few key data points:
What changed (the data that was modified)
When it changed (shown as a sequence number)
How much information to capture (Stream view type)
The stream record looks as such:
{
"eventID": "1234567890",
"eventName": "MODIFY",
"eventVersion": "1.1",
"eventSource": "aws:dynamodb",
"awsRegion": "us-east-1",
"dynamodb": {
"Keys": {
"Id": {"S": "123"}
},
"NewImage": {
"Id": {"S": "123"},
"Status": {"S": "UPDATED"},
"LastModified": {"S": "2023-01-01"}
},
"OldImage": {
"Id": {"S": "123"},
"Status": {"S": "PENDING"},
"LastModified": {"S": "2023-01-01"}
},
"SequenceNumber": "111",
"SizeBytes": 26,
"StreamViewType": "NEW_AND_OLD_IMAGES"
}
}
Choosing What to Capture
Since DynamoDB captures every change, we need to be sure we select the appropriate stream view type for what we need. There are four ways to capture changes, and each provides a different level of detail:
1. KEYS_ONLY
{
"userId": "123"
}
Best for: When you only need to know something changed
Example: Triggering a cache refresh
2. NEW_IMAGE
{
"userId": "123",
"name": "John",
"status": "active"
}
Best for: When you only care about the current state
Example: Updating a search index
3. OLD_IMAGE
{
"userId": "123",
"name": "John",
"status": "pending"
}
Best for: When you need to know the previous state
Example: Tracking status changes
4. NEW_AND_OLD_IMAGES
{
"old": {
"userId": "123",
"status": "pending"
},
"new": {
"userId": "123",
"status": "active"
}
}
Best for: When you need to see what changed
Example: Audit logging, compliance tracking
How DynamoDB Streams Process Data
The Package Delivery Analogy
Let’s imagine a package delivery system for our stream records:
📦 Package = Data Change
📋 Tracking Number = Sequence Number
🏭 Sorting Center = Shard
How It Works
The figurative conveyor belt
Every data change resembles a package on a conveyor belt
Like actual packages, our figurative stream record packages receive a tracking number.
Packages move in a strict order, just like your data changes.
The imaginary sorting center
Packages are grouped into different sorting centers, we call these centers shards.
Each center (shard) handles a smaller portion of the overall packages
When a center gets too busy, a new shard is created
Centers operate for 24 hours before closing (or 1 year if you’re using Kinesis Data Streams)
The world wide delivery route
Our conveyor belt must process older packages before newer ones
Ensures orderly, predictable processing
For DynamoDB streams - you’ll have to process with Lambda or the DynamoDB Streams Kinesis Adapter.
For Kinesis Data Streams - you can use a mix of Lambda, Kinesis Data Firehouse, and AWS Glue Streaming ETL
Key Guarantees
There are several key points we must understand when designing an application for a stream specific stream type. We can expect the following:
✅ At-least-once delivery for Kinesis Data Streams for DynamoDB: DynamoDB is a distributed system, and distributed systems sometimes send the same message twice (or more) to ensure delivery. In other words, there is a chance you could receive a duplicate record in your stream. We call this at least once delivery.
✅ Exactly once delivery for DynamoDB Streams: We don’t have to worry as much about accounting for duplicates with this option.
✅ 24-Hour Storage: Records available for 24 hours (remember, 1 year for Kinesis Data Streams)
✅ Order Preserved: Order of stream records appear in the same sequence as the table modifications. For Kinesis Data Streams, the timestamp attribute can be used to identify the order in which the changes occured.
✅ You can enable both stream types on the same table.
During the design phases you must take into account and plan accordingly for these guarantees. But what could this look like?
Account for at-least-once processing by using idempotency logic, depending on which stream type you’re using.
Process records promptly to avoid data loss, especially if you’re using the basic DynamoDB stream.
Know your expected throughput needs. Kinesis Data Streams has unlimited throughput, whereas normal DynamoDB streams are subject to throughput quotas.
Limitations and Constraints
Important limitations to consider:
You can have a maximum of 2 processes that can read from the same stream shard at the same time. This quota increases to 5 processes for Kinesis Data Streams for DDB. If you have enhanced fan-out enabled, you can raise that amount to 20!
The largest and most used regions such as US East 1 & 2, US West 1 & 2, South America, Europe and Asia Pacific regions allow 40,000 provisioned write capacity units. All others are 10,000. You can see more details for your region here.
For DynamoDB streams for Kinesis you can only stream data within the same AWS account and region (sorry folks, no cross-account or multi-region failover here). Additionally, you can only stream data to one Kinesis data stream.
Architectural Patterns
Let's take a look at a few architecture patterns for DynamoDB streams and discuss in what scenario it could be used.
Single responsibility pattern
This one is straight forward and is great for when your use case handles a single responsibility, such as sending an email confirmation.

Lets illustrate how you might implement the Lambda function for this pattern:
def lambda_handler(event, context):
for record in event['Records']:
# Get the new image from the stream record
if 'NewImage' in record['dynamodb']:
new_image = record['dynamodb']['NewImage']
# Process the new image
process_item(new_image)
def process_item(item):
# Add your processing logic here
pass
Fan-out Pattern
What happens when you need to send notifications of a change to multiple downstream services? That's where the fan out pattern comes in to play. This one is a standard pattern in the world of serverless architectures. The fan out pattern is obvious choice when changes to a record need to be processed by many downstream services. In the architecture and code sample below, we are using the stream to make updates to products in an e-commerce application.
The flow is the following:
A change is made to the table
The stream captures the change
A set of Lambda functions processes the change independently
Each Lambda handles a different component of business logic. In this case, we update our inventory system, forward data to the shipping service, and then send record metadata to our third part analytics or application monitoring service like Datadog or Splunk.

# Consumer 1: Update inventory
def update_inventory(event, context):
for record in event['Records']:
add_record_to_inventory_service(record)
# Consumer 2: Shipping service
def forward_to_shipping_service(event, context):
for record in event['Records']:
update_shipping_service(record)
# Consumer 3: Analytics or application monitoring
def observability_processor(event, context):
for record in event['Records']:
update_external_observability_service(record)
While this pattern is a fairly simple one using DynamoDB streams and Lambda, we need to be mindful of a few things.
Record changes in the stream will run all 3 Lambda functions regardless if the record changes needs to trigger all 3 services. We may incur unintended spend by using this pattern if we don't need all 3 consumers processing every record change.
If one Lambda function fails for some reason (remember, we must account for failure in the design of the solution), and it is not addressed until after the stream data expires, we will lose the data. This may have unintended downstream effects for your users.
If you only want to have 1 or 2 services out of the 3 process data from the stream, this pattern may not be the right choice.
Event Broadcasting
For the event broadcasting pattern, we can use a social media post management system is a good candidate for illustration. In this example, we track the changes to a posts table. A Lambda is watching for changes to the DynamoDB stream and then broadcasts that change to an SNS topic. Several subscribers are attached to the SNS topic, and each subscriber will operate independently from the others. There are many other examples in the wild using other services like SQS —> SNS —> Lambda, where a filter pattern is used to subscribe many Lambda functions. Thus, this pattern is not strictly limited to DynamoDB streams!
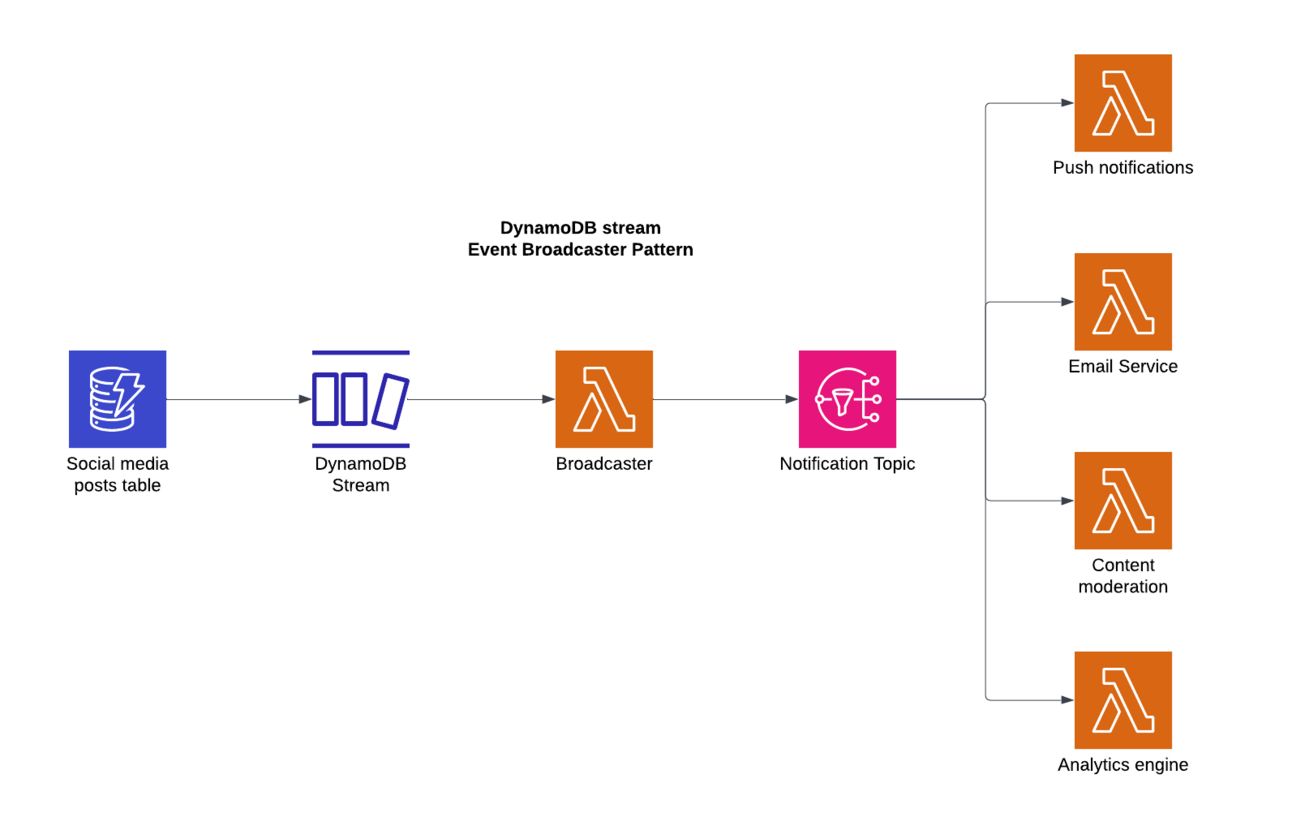
Below I have outlined few code examples of what this flow could look like, given the event below:
{
"postId": "post123",
"userId": "user456",
"content": "Check out my new photo!",
"type": "photo",
"status": "published",
"timestamp": "2024-09-01T10:00:00Z"
}
# The Lambda handler that serves as the broadcaster
def lambda_handler(event, context):
sns_client = boto3.client('sns')
for record in event['Records']:
# Only process if it's a new or modified post
if record['eventName'] in ['INSERT', 'MODIFY']:
post = record['dynamodb']['NewImage']
# Create the event message
message = {
'eventType': record['eventName'],
'postId': post['postId']['S'],
'userId': post['userId']['S'],
'contentType': post['type']['S'],
'status': post['status']['S'],
'timestamp': post['timestamp']['S']
}
# Add message attributes, this is useful for filtering on the topic
# you can add a filter so that only certain subscribers pick up
# specific event types. You may not want all subscribers to pick up
# every event that is sent to the topic
message_attributes = {
'contentType': {
'DataType': 'String',
'StringValue': post['type']['S']
},
'eventType': {
'DataType': 'String',
'StringValue': record['eventName']
}
}
# Publish to SNS
sns_client.publish(
TopicArn=os.environ['SNS_TOPIC_ARN'],
Message=json.dumps(message),
MessageAttributes=message_attributes
)
# Push Notification Service
def handle_push_notifications(event, context):
message = json.loads(event['Records'][0]['Sns']['Message'])
if message['eventType'] == 'INSERT':
send_push_notification(
user_id=message['userId'],
message="Your post has been published!"
)
# Search Indexing Service
def update_search_index(event, context):
message = json.loads(event['Records'][0]['Sns']['Message'])
elasticsearch.index(
id=message['postId'],
document=message
)
# Content Moderation Service
def moderate_content(event, context):
message = json.loads(event['Records'][0]['Sns']['Message'])
if message['eventType'] == 'INSERT':
trigger_content_review(message['postId'])
I like this architecture for a few reasons:
The subscriber services are decoupled from each other. If one fails, which it inevitably will, the other services are unaffected.
We can add new subscriber services to the topic as needed (up to 12.5 million for standard topics, if you were curious!)
Besides the actual Lambda broadcaster, there are no direct dependencies for our downstream consumer services.
If we use filter patterns on the SNS topic we can control which services run based on the record type or other messageAttributes that we see coming into the topic.
Conclusion
We have explored the fundamentals of streams like at-least-once delivery, twenty-four hour retention, and stream process ordering. We highlighted a few key differences between DynamoDB streams and Kinesis Data Streams for DynamoDB. We also touched on three architectural patterns: single responsibility, fan-out, and event broadcasting. Each pattern serves different needs, from simple email notifications to complex, multi-service processing. In Part 2 of this series, we'll tackle the critical aspects of failure handling and resilience - essential knowledge for building production-ready systems with DynamoDB Streams. Whether you're processing financial transactions or managing inventory, understanding these patterns and their appropriate use cases is key to building reliable, scalable applications.